In general, most people in the organization don't really bother to think how things work. It's just magic on the backend that allows their data to be backed up. They don't really grok that the hundreds of TiB of blocks they've pushed at the array actually only took up a few tens of TiB. Unfortunately, like any storage device, deduplicating storage arrays can run out of space. When they do, people's lack of understanding of what goes on under the covers really comes to the fore. You'll hear plaintive cries of "but I deleted 200TiB - what do you mean there's only 800GiB free, now??"
Given our data storage tendencies, if we realize a 10% return of the amount deleted at the backup server, it's a good day. When we get more than that, it's gravy. Trying to verbally-explain this to folks who don't understand what's going on at the arrays, is mostly a vain effort.
To try to make things a bit more understandable, I came up with three simplified illustrations of array utilization patterns with respect to backup images and the nature of the application's data change patterns. Each of the illustrations should be interpreted to represent data sets that are backed up. Each box represents a same-sized chunk of data (e.g., 200GiB). Each letter represents a unique segment of data within a larger data-set. Each row represents a backup job - with time being represented oldest to most recent ordered top to bottom. Each column represents a copy of a unique chunk of data.
All of what follows is massive over-simplification and ignores the effects of file-compression and other factors that can contribute to space-used on or reclaimed from an array.
100% Data Change Rate:
 |
| 100% Change-rate (full backup to full backup) |
The application's full data-set is represented by the five boxes labeled "A" through "E". Changes to a given segment are signified by using the prime symbol. That is, "A'" indicates that data-segment "A" has experienced a change to every block of its contents - presumably sufficient change to prevent the storage array from being able to deduplicate that data either against the original data-segment "A" or any of the other lettered data-segments.
This diagram illustrates that, between the time the first and the last full backup has occurred, all of the data-segments have changed. Further, the changes happened such that one (and only one) full data-segment changed before a given incremental backup job was run.
Given these assumptions about the characteristics of the backup data:
- if one were to erase only the original full backup from the the backup server, up to 100% of the blocks consumed at the array might be returned to the pool of available blocks.
- If one were to erase the original full backup and any (up to all) of the incrementals, the only blocks that would be returned to the pool of available blocks would be the ones associated with the initial full backup. None of the blocks associated with the incremental backups would be returned. Thus, the greater the number of incrementals deleted, the lower the overall yield of blocks returned to the available blocks pool would be. Thus, if all of the backup images - except for the most recent full backup - were deleted, the maximum return-yield might be as high as 50% of the blocks erased at the backup host.
This would be a scenario where you might hear the "but I deleted xGiB of data and you're telling me only half that got freed up??"
100% Growth Rate:

The above is kind of ugly. Assuming no deduplicability between data segments, each backup job will consume additional space on the storage array. Assuming 200GiB segments, the first full backup would take up 1TiB of space on the array. Each incremental would consume a further 200GiB. By the time the last incremental has run, 2TiB of space will be consumed in the array.
That ugliness aside, when the second full backup is run, almost no additional disk space will be consumed: the full backups segments would be duplicates of all prior jobs.
However, because the second full backup duplicates all prior data, erasing the first full backup and/or any (or all) of the incrementals would result in a 0% yield of the deleted blocks being returned to the available blocks pool. In this scenario, the person deleting data on their backup server will be incredulous when you tell them "that 2TiB of image data you deleted freed up no additional space on the array". Unfortunately, they won't really care that the 4TiB of blocks that they'd sent to the array only actually consumed 2TiB of space on the array.
20% Data Change Rate:
 The above diagram attempts to illustrate a data set that changes continuously changes 20% of the data set - with no growth in the data set-size - between full backups. Further, only one chunk of data is changing - 80% of the original data-set remains completely unchanged between backups. A given full backup is represented by five lettered-boxes on a single line. Incremental backups are represented by single lettered-boxes on a single line.
The above diagram attempts to illustrate a data set that changes continuously changes 20% of the data set - with no growth in the data set-size - between full backups. Further, only one chunk of data is changing - 80% of the original data-set remains completely unchanged between backups. A given full backup is represented by five lettered-boxes on a single line. Incremental backups are represented by single lettered-boxes on a single line.
The application's full data-set is represented by the five boxes labeled "A" through "E". Changes to a given segment are signified by using the prime symbol. That is, "A'" indicates that data-segment "A" has experienced a change to every block of its contents - presumably sufficient change to prevent the storage array from being able to deduplicate that data either against the original data-segment "A" or any of the other lettered data-segments.
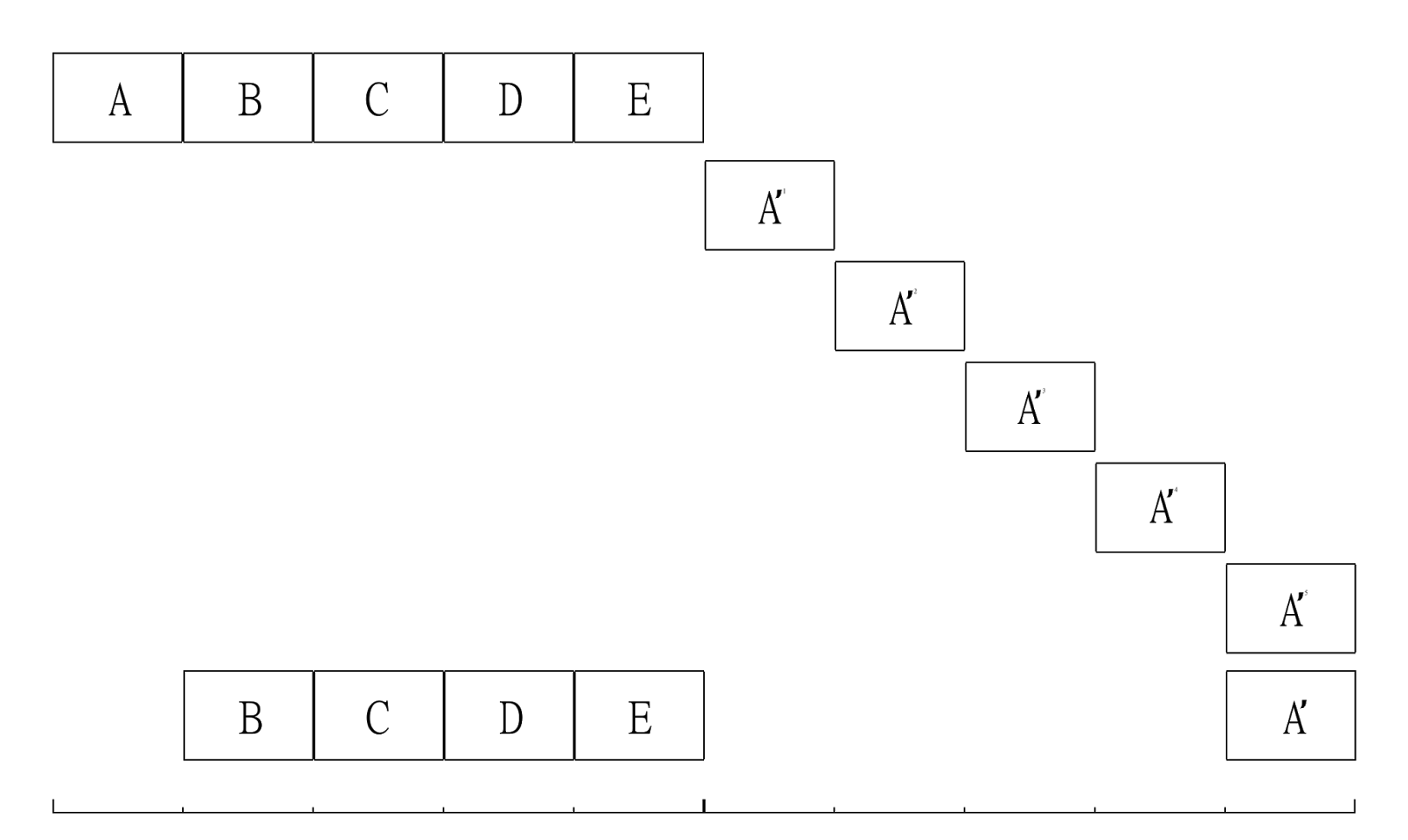
The application's full data-set is represented by the five boxes labeled "A" through "E". Changes to a given segment are signified by using the prime symbol. That is, "A'" indicates that data-segment "A" has experienced a change to every block of its contents - presumably sufficient change to prevent the storage array from being able to deduplicate that data either against the original data-segment "A" or any of the other lettered data-segments.
Assuming 200GiB data-segments, the first full backup plus the incrementals would have resulted in 2TiB having been sent to the array. The total space consumed on the array would be similar.
If the first full backup is erased, of the 1TiB erased, up to 200GiB would be returned to the free blocks pool. This is because the first full backup and the second full backup overlap by 800GiB worth of deduplicated (non-unique) data.
In the above image, each of the first four incrementals has unique data not found in the second full backup. The fifth incremental's data is incorporated into the last full backup. Thus, deleting each of the first four incrementals may return up to 200GiB of blocks to the free blocks pool. Deletion of the last incremental will result in no blocks being returned to the free blocks pool. By extension, if the first full backup plus all of the incrementals are deleted, though 2TiB of data would be deleted at the backup server, only 1TiB would be returned to the free block pool.
Each of the above illustrations aside, unless you're undertaking the very expensive practice of allocating one deduplication pool per application/data-set, the deletion-yields tend to become even more apalling. The compression and deduplication algorithms in your array may have found storage optimizations across data sets. End result will be that your deduplication ratios will go down, but your actual blocks consumed on the array won't go down nearly as quickly as the folks deleting data might hope.
Similarly poor deletion-yields will occur when your backup system is keeping more than just two full backups. This is because the amount of aggregate overlaps across backup sets will be greater as the number of retained full backups increases.